人工智能
P 和 NP
P 类问题是指能够在多项式时间内解决的问题 NP 类问题是指能够在多项式时间内验证一个解对不对的问题,所有 P 问题都是 NP 问题。 NP-hard: 比 NP 还要难,任意一个 NP 问题都能在多项式时间规约为 NP-hard 问题 NPC: NP 完全问题,即是 NP 问题,又是 NP-hard 问题
SAT 问题(第一个 NPC 问题). 该问题的基本意思是,给定一系列布尔变量以及它的约束集,是否存在一个解使得它的输出为真。 如果找到一个多项式内能被解决的 npc 问题的解决方法,那么 P=NP.
encoder-decoder
encoder-decoder 结构,基本思想就是利用两个 RNN, 一个 RNN 作为 encoder, 另一个 RNN 作为 decoder.
Decoder RNN 在预测的时候,需要把上一个神经元的输出作为下一个神经元的输入,不断的预测下一个词,直到预测输出了结束标志符 <END> , 预测结束。
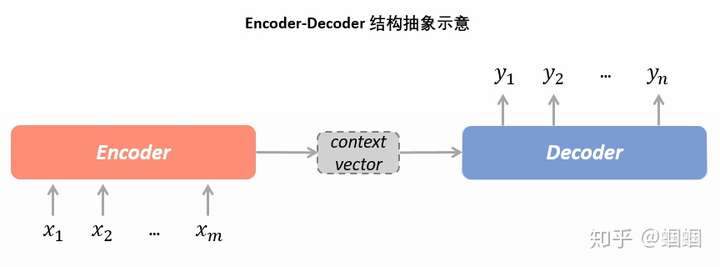
seq2seq
seq2seq 属于 encoder-decoder 结构的一种。
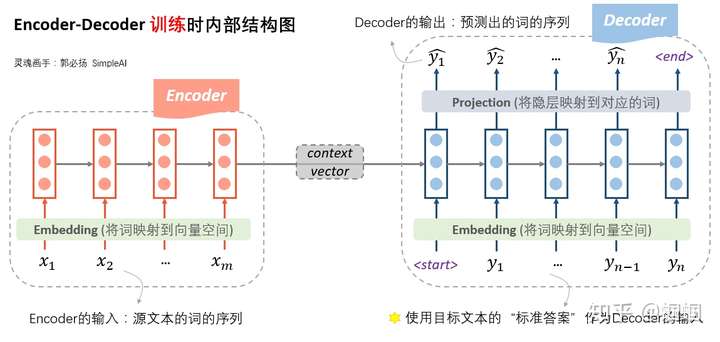
transformer
Transformer 的本质上是一个 Encoder-Decoder. 编码器由 6 个编码 block 组成,同样解码器是 6 个解码 block 组成,编码器的输出会作为解码器的输入。 每个 encoder 有两层,一层是 self-Attention(Multi-head) 机制,另一层是前馈神经网络。 首先可以利用 WordEmbedding 将一个单词转换成固定长度的向量表示
Self-Attention 核心内容是为输入向量的每个单词学习一个权重。 对于 decoder 来讲,我们注意到有两个与 encoder 不同的地方,每个 decoder 有三层 . 一个是第一级的 Masked Multi-head, 另一个是第二级的 Multi-Head Attention 不仅接受来自前一级的输出,还要接收 encoder 的输出,第三级也是前馈神经网络。
图灵测试
让计算机来冒充人。如果不足 70%的人判对,也就是超过 30%的裁判误以为在和自己说话的是人而非计算机,那就算作成功。 2014 年 6 月 8 日,一台计算机(计算机尤金·古斯特曼并不是超级计算机,也不是电脑,而是一个聊天机器人,是一个电脑程序)成功让人类相信它是一个 13 岁的男孩,成为有史以来首台通过图灵测试的计算机。这被认为是人工智能发展的一个里程碑事件。
CNN
CNN 的构成是卷积层+池化层+全连接
卷积层
卷积层就是一个卷积核对一个矩阵进行操作,以二维为例,卷积核作为一个小二维数组(存在自身的值), 沿着左上角对齐矩阵,然后将重合部分的每对数进行相乘,然后将这些数相加,填入结果矩阵中,然后根据步幅移动到下一个位置,直到把结果数组填满。 对于更多维的情况,卷积核的通道数(也就是第三维的大小)和矩阵是相同的。四维的情况一般是一个批次的数据,数据的标号作为第四维。
池化层
池化层也叫下采样层。池化层也是一个小数组,不过自身并没有数字。他和卷积核的移动逻辑相同,就是对于重合部分,它直接取最大值(也有取平均值的), 填入结果数组。 可以用来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。在图像处理中,可以在目标平移或者旋转而导致卷积结果有偏移时进行校正(经多次池化后结果一样), 也可以增大感受野。
全连接
全连接相当于一个分类器。全连接层起到将学到的”分布式特征表示”映射到样本标记空间的作用。
RNN
RNN 全程循环神经网络。其输出不但与当前输入和网络的权值有关,而且也与之前网络的输入有关;其允许我们对向量的序列进行操作:输入可以是序列,输出也可以是序列,在最一般化的情况下输入输出都可以是序列。 对于 NLP 来说,RNN 理论上可以往前看(往后看)任意多个词。
激活函数
ReLU 函数
f(x) = max(0, x)
sigmoid
\[θ(x)=\frac{1}{1+e^{-x}}\]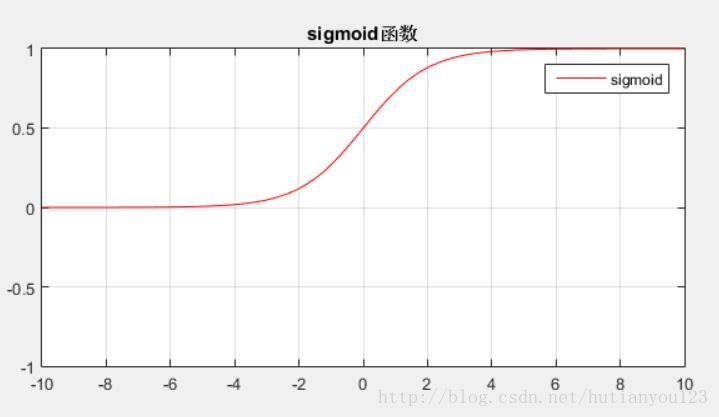
过拟合
机器在学习全局特征的同时,又过度学习了局部特征。导致泛化能力不够。模型在训练集上表现的很好,但是在交叉验证集合测试集上表现一般。
解决方案
- 增大数据N。可以直接从数据的源头获取更多的数据,也可以通过对原有的图像的旋转,平移等,获取到更多的数据。
- 简化模型,可能是模型太复杂,导致数据相对不足。
- 降低特征的数量
- Dropout 指的是在训练过程中每次按一定的概率(比如 50%)随机地“删除”一部分隐藏单元(神经元)
- early stopping 。每一个 epoch 结束的时候,检查准确度,如果准确度连续多次没能提升到历史最高,那么就终止训练。
- 集成学习方法。集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。比如随机森林算法,它就是多个决策树的组合。
- 交叉验证
交叉验证
交叉验证的基本思想是把在某种意义下将原始数据 (dataset) 进行分组,一部分做为训练集 (train set), 另一部分做为验证集 (validation set or test set), 首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型 (model), 以此来做为评价分类器的性能指标
聚类
聚类是一种无监督的学习方法。
kmeans
1、定义距离,定义初始质心 2、循环计算每个点到每个质心的距离,然后确定每个点属于的类别(距离最小的), 并记录该点到该点质心的距离 3、确认每类下的点,然后计算这一类点的平均值,并把这个值确立为该类的新质心 4、如果所有数据都确定了属于某一类(不再更新), 则分类完成
线性回归和逻辑回归
线性回归
监督学习,根据数据学习映射关系,利用该映射关系对未知的数据进行预估
逻辑回归
监督学习,解决二分类问题。逻辑回归就是将线性回归的 $(-\infty, +\infty)$结果,通过 sigmoid 函数映射到 $(0, 1)$之间。以 1/2 作为决策边界
支持向量机 (SVM)
也是分类问题,最大化最近数据点,如果不能用直线划分,那么就升维,在高纬度进行划分,反映到低维上就是曲线